Microsoft AI Frontiers researchers develop ECHO, a training method that adds environment prediction loss to GRPO so CLI agents build internal world models of terminal environments during reinforcement learning
Qwen3 evaluations show higher pass rates with no added compute.
@DimitrisPapail @ChengleiSi This is nice work, so sorry for distracting from the substance, but I'm genuinely curious:
> This work was done at AI Frontiers, a boutique research lab inside Microsoft Research.
What does "boutique research lab" mean here?
http://x.com/i/article/2056344151235387392
@AlexGDimakis @DimitrisPapail @ChengleiSi Hehe
@giffmana @DimitrisPapail @ChengleiSi Lucas, in a world of commodity models and scaled slop, a boutique research labs proposes something more deliciously bold: Think of Mozambique cashmere agents, asymmetrical overall environments and locally sourced world model custom losses.
@DimitrisPapail Cool stuff. I'd like to see a JEPA version though. A lot of the output of terminals is not useful to predict _most of the time_. You could at least speed up learning if you abstracted away some of the detail.
http://x.com/i/article/2056344151235387392
@DimitrisPapail This work is so cool as always @DimitrisPapail , and you are too kind!!
I'm just glad we did this before @lateinteraction and his amazing students :p
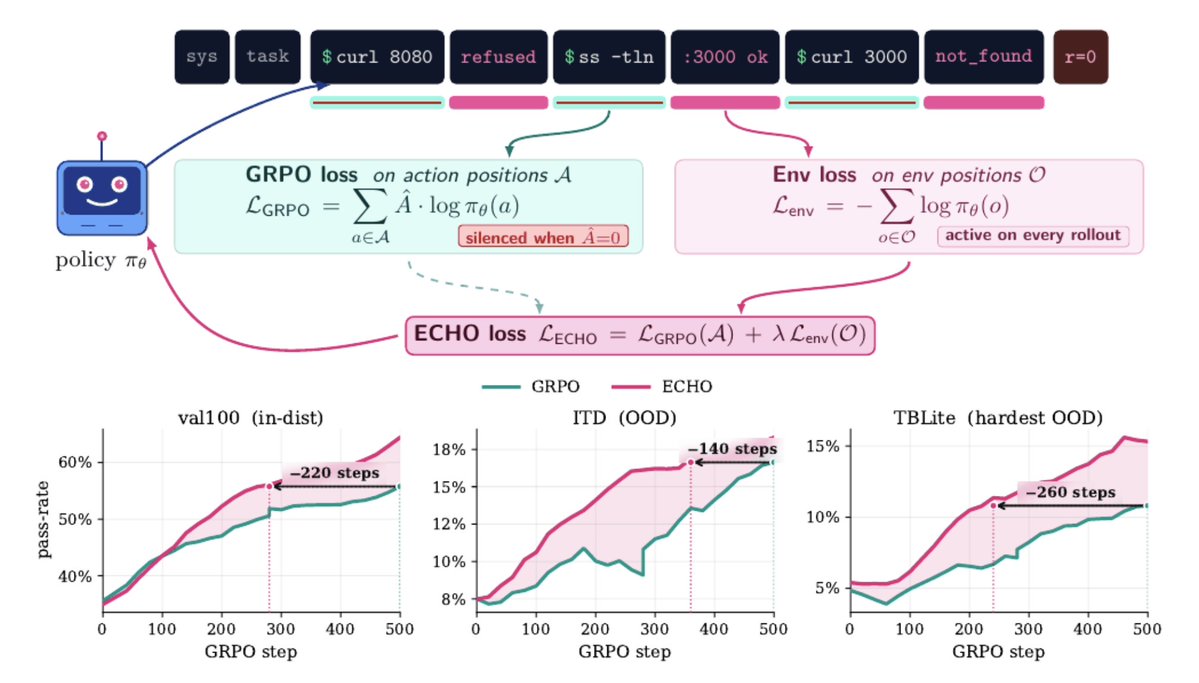
Improve your agents with one weird trick: ECHO says, when you SFT an agent, do not train it to predict only the agent replies, but also the terminal responses. When you GRPO, you use the same rollout to predict the terminal responses with cross entropy loss. Its basically free and gets extra supervision from the CLI. This apparently helps the model develop a 'world model' of the terminal, and improves performance, which was very surprising to me.
http://x.com/i/article/2056344151235387392
@giffmana @DimitrisPapail @ChengleiSi Lucas, in a world of commodity models and scaled slop, a boutique research labs proposes something more deliciously bold: Think of Mozambique cashmere agents, asymmetrical overall environments and locally sourced world model custom losses.
@DimitrisPapail @ChengleiSi This is nice work, so sorry for distracting from the substance, but I'm genuinely curious: > This work was done at AI Frontiers, a boutique research lab inside Microsoft Research. What does "boutique research lab" mean here?
Exciting results & direction with learning from signals from the environment—with implications for continual learning about the world. @DimitrisPapail @MSFTResearch
http://x.com/i/article/2056344151235387392
Turns out training your agent to be a world simulator improves its accuracy of solving problems
Internalizing world modeling as a native ability for agents.
Very rarely you stumble on a method that's simple, obvious in hindsight, free, and touches on every problem you care about: CLI agents, continual learning, self-improvement, world models.
ECHO is one of those
http://x.com/i/article/2056344151235387392
@ysu_nlp @VaishShrivas i feel in many ways the terminal is very unique because it returns the environment's response to policy actions in the same format as the actions themselves: tokens. Which is computed for free, and the trainer ALREADY computes logits etc for. So it's 100% free lunch... kinda wild
nice work by @DimitrisPapail and @VaishShrivas! this work is reinforcing a recent trend that tries to make foundation models jointly predict future states (aka 'world models') and actions instead of actions alone. we're seeing it in different forms, like World Action Models in embodied agents, or implicit world modeling in Early Experience (https://arxiv.org/abs/2510.08558). also some interesting link to on-policy self-distillation. shared learning here is, there's still rich supervision signals that are underexplored. such signals were hard to exploit in classic ML, but foundation models have made it possible, potentially creating a recursive self-improvement loop.
@willccbb Humbled by the kind words. I also agree, it's bitter pilled AF
god what a beautiful objective. i wonder how general you can push this. best non-distillation answer ive seen for knowledge acq during RL, feels bitter-pilled in a way that most self-teaching methods aren’t.
@willccbb yup! can also work in the absence of the normal GRPO loss which is also kinda nuts (as long as your tasks and current model are in some sense rich). I have no freaking clue what the ceiling is here

@DimitrisPapail i’d given up on the idea of using the rollout env tokens directly but had always still had the adv term in there (which doesn’t work, for reasons i now understand better). but dropping it makes so much more sense
@willccbb good question. will try it, makes a lot of sense.
@DimitrisPapail i’d be very curious to see it on small-taskset search with an efficiency bonus. does the model learn new facts and not need to search every time?
@BlackHC @willccbb Eh what’s six months in the infinite of the universe
@willccbb I think we tried something like that last year or so 😅 so maybe open-source is way more than six months behind in some areas
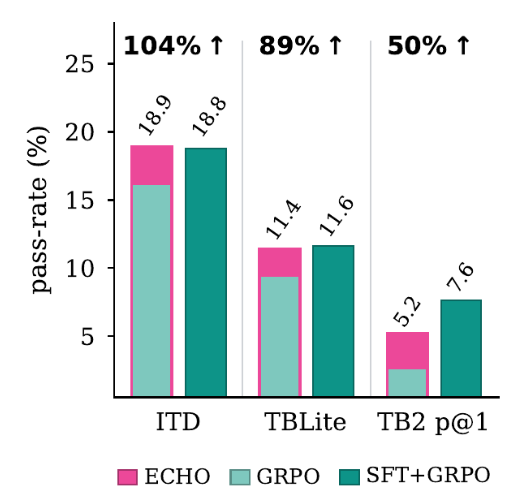
One aspect that also appreciate about ECHO is that it can reduce reliance on SFT data to jump start a CLI agent.
An example: comparing with the OpenThoughts-Agent which is Qwen3-8B SFT’d on ∼15k GLM-4.6 trajectories, ECHO on base Qwen and NO SFT closes the gap.
Kinda cool!
http://x.com/i/article/2056344151235387392
Lol you can continual learn by training on terminal outputs WITHOUT REWARDS

http://x.com/i/article/2056344151235387392
Prediction: by end of 2026 Echo will be part of standard agent RL trainers.
FREE LUNCH FOR EVERYONE
http://x.com/i/article/2056344151235387392
@NovaSkyAI here's a simple skyRL patch to train better CLI agents, for free
http://x.com/i/article/2056344151235387392
@giffmana @ChengleiSi A small group, of talented people, that are given free space to explore ideas that matter in the broader scope of AI, and specifically the area of computer use agents, but don't cost 1M to test :)
@DimitrisPapail @ChengleiSi This is nice work, so sorry for distracting from the substance, but I'm genuinely curious: > This work was done at AI Frontiers, a boutique research lab inside Microsoft Research. What does "boutique research lab" mean here?
@giffmana @ChengleiSi I came up with the phrasing, because it reminds me of how I'd describe with two words DM in its early days. One can only hope to come approximately close to that intellectual and technical space.
@giffmana @ChengleiSi A small group, of talented people, that are given free space to explore ideas that matter in the broader scope of AI, and specifically the area of computer use agents, but don't cost 1M to test :)
@giffmana @ChengleiSi also thanks for reading up to that part :D i know you have ton of cool stuff to work on today, so I'm grateful for your time.
@giffmana @ChengleiSi I came up with the phrasing, because it reminds me of how I'd describe with two words DM in its early days. One can only hope to come approximately close to that intellectual and technical space.
I'm just glad we did this before @lateinteraction and his amazing students :p
http://x.com/i/article/2056344151235387392
@AlexGDimakis @giffmana @ChengleiSi lol
@giffmana @DimitrisPapail @ChengleiSi Lucas, in a world of commodity models and scaled slop, a boutique research labs proposes something more deliciously bold: Think of Mozambique cashmere agents, asymmetrical overall environments and locally sourced world model custom losses.
@roydanroy I agree! We have some thoughts but they are related to compaction rather than Jepa.
@DimitrisPapail Cool stuff. I'd like to see a JEPA version though. A lot of the output of terminals is not useful to predict _most of the time_. You could at least speed up learning if you abstracted away some of the detail.
Just realized ECHO fits a years long obsession of transformers and computers.
"Looped Transformers are Computers" "Can You Train a Transformer to be Computer?" And now "Can You Train a Transformer to Simulate a Computer?"
Blame my hobbyist love of theory of computation
http://x.com/i/article/2056344151235387392
@ziv_ravid Thanks for checking it out Ravid!
Very cool work. I also think that signal from terminal is so underestimate (similar to RLM). and to have a strong opinion on the title is also my thing 😁
World modeling. Faster RL. Self-improvement without verifiers.
All from one extra loss term on your favorite open-weights CLI agent.
Happy Monday!
http://x.com/i/article/2056344151235387392
@ChenhaoTan Thanks for checking out! I agree. You don't get too many of those in your career, so happy we stumbled upon it
Always a good sign that you are surprised that something has not been done before!
@willccbb I think we tried something like that last year or so 😅 so maybe open-source is way more than six months behind in some areas
god what a beautiful objective. i wonder how general you can push this. best non-distillation answer ive seen for knowledge acq during RL, feels bitter-pilled in a way that most self-teaching methods aren’t.
A fun result: training to predict terminal output significantly accelerates RL for terminal agents.
http://x.com/i/article/2056344151235387392
god what a beautiful objective. i wonder how general you can push this. best non-distillation answer ive seen for knowledge acq during RL, feels bitter-pilled in a way that most self-teaching methods aren’t.

http://x.com/i/article/2056344151235387392
a litmus test i’ve been thinking about for continual learning is bounding lifetime retrieval count per fact. a model should use tools to look things up, but gradually compound fuzzy memories of things they’ve searched, and eventually not need search. this could maybe work here
god what a beautiful objective. i wonder how general you can push this. best non-distillation answer ive seen for knowledge acq during RL, feels bitter-pilled in a way that most self-teaching methods aren’t.
it also offers a clean bridge from pretraining to RL, which is another property i think we should expect from general continual learning methods. initially, everything is env tokens
a litmus test i’ve been thinking about for continual learning is bounding lifetime retrieval count per fact. a model should use tools to look things up, but gradually compound fuzzy memories of things they’ve searched, and eventually not need search. this could maybe work here
@DimitrisPapail i’d given up on the idea of using the rollout env tokens directly but had always still had the adv term in there (which doesn’t work, for reasons i now understand better). but dropping it makes so much more sense
@willccbb Humbled by the kind words. I also agree, it's bitter pilled AF
@DimitrisPapail i’d be very curious to see it on small-taskset search with an efficiency bonus. does the model learn new facts and not need to search every time?
@willccbb yup! can also work in the absence of the normal GRPO loss which is also kinda nuts (as long as your tasks and current model are in some sense rich). I have no freaking clue what the ceiling is here
nice work by @DimitrisPapail and @VaishShrivas!
this work is reinforcing a recent trend that tries to make foundation models jointly predict future states (aka 'world models') and actions instead of actions alone.
we're seeing it in different forms, like World Action Models in embodied agents, or implicit world modeling in Early Experience (https://arxiv.org/abs/2510.08558). also some interesting link to on-policy self-distillation.
shared learning here is, there's still rich supervision signals that are underexplored. such signals were hard to exploit in classic ML, but foundation models have made it possible, potentially creating a recursive self-improvement loop.

http://x.com/i/article/2056344151235387392
@DimitrisPapail @VaishShrivas It is, largely because 1) it’s a language-native environment (a bit privileged in that sense), 2) there’s terminal reward from the RL tasks. Impressive findings nonetheless. Coding and CLIs are quite fundamental
@ysu_nlp @VaishShrivas i feel in many ways the terminal is very unique because it returns the environment's response to policy actions in the same format as the actions themselves: tokens. Which is computed for free, and the trainer ALREADY computes logits etc for. So it's 100% free lunch... kinda wild
incredible Are we missing any other free, perfect, dense verifiers?
http://x.com/i/article/2056344151235387392
Always a good sign that you are surprised that something has not been done before!
http://x.com/i/article/2056344151235387392
Very cool work. I also think that signal from terminal is so underestimate (similar to RLM). and to have a strong opinion on the title is also my thing 😁
http://x.com/i/article/2056344151235387392
How do machines build a mental map of reality? 🧠
Check out this frontier investigation into *world models* from our team at @ms_aifrontiers. Proud to see @DimitrisPapail and colleagues pushing the boundaries of how we think about AI reasoning.
World modeling. Faster RL. Self-improvement without verifiers. All from one extra loss term on your favorite open-weights CLI agent. Happy Monday!
@DimitrisPapail
World modeling. Faster RL. Self-improvement without verifiers. All from one extra loss term on your favorite open-weights CLI agent. Happy Monday!

Wonderful. The terminal is the world to an agent. It learns to model the world
@DimitrisPapail great work @DimitrisPapail
http://x.com/i/article/2056344151235387392
Super cool work. I wonder if training not just on the environment response but on the entire input output pair would work better? So L_env on both the (tool_call_action_input, env_output) tokens. L_grpo on thinking/action tokens etc
Training without the GRPO term and only getting the model to learn to predict environmental responses works too! (world modelling!)
Wonderful. The terminal is the world to an agent. It learns to model the world
Very rarely you stumble on a method that's simple, obvious in hindsight, free, and touches on every problem you care about: CLI agents, continual learning, self-improvement, world models. ECHO is one of those
FYI, I will bet my last nickel this is part of Amthropics secret sauce
Wonderful. The terminal is the world to an agent. It learns to model the world
very inspiring work by @DimitrisPapail and @VaishShrivas on adding terminal response prediction as an auxiliary loss to grpo for training terminal agents
this reminds me of an old line of work on unsupervised auxiliary tasks or pseudo rewards for tackling challenges in sparse reward settings and exploration. one of the most memorable papers - unreal from 10 years ago (https://arxiv.org/pdf/1611.05397) by @maxjaderberg, @VladMnih, @wojczarnecki, tom schaul, @jzl86, david silver, and @koraykv proposed multiple auxiliary tasks like maximizing pixel changes, network feature control, reward prediction, and experience replay for training a3c agents in first-person 3d game environments
that is to say there are still many good low-hanging fruits in designing good auxiliary tasks and pseudo rewards for training llm agents in different environments. for example, auxiliary tasks like artifact control, novel state discovery, and so on may be interesting to try out
BUT be careful of reward hacking such as the well-known gaussian noise television problem

http://x.com/i/article/2056344151235387392