METR publishes its first Frontier Risk Report concluding that unreleased models from Anthropic, Google, Meta, and OpenAI could execute minimal rogue deployments due to monitoring weaknesses
Detection would likely occur within days from reward hacking.
Too ubiquitous to METR

On Jan 12, I joined METR to lead writing for our first Frontier Risk Report. The last 18 weeks have been a series of wild sprints to pitch labs, negotiate contracts, analyze questionnaires, negotiate redactions, and write this thing! I'll be on TBPN at 12:30 to discuss it!
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Rob did a great job breaking down our new Frontier Risk Report!
METR investigated what a rogue AI could secretly get away with inside a frontier AI lab, in close collaboration with OpenAI, GDM, Anthropic and Meta. Including sending a red-teamer into Anthropic to playact 'evil Claude' for 3 weeks. Here's what stands out to me from their new 320-page report: 00:00 What could an unreleased AI get away with? 01:54 Motive: Why grab more compute? 05:46 Opportunity: YOLO mode and jailbreaks 11:02 Means: Brilliant idiots in data centres 15:45 We have to test unreleased models... 18:29 ...especially if AI R&D is coming in 2028
@alth0u It's becoming common inside frontier labs for people to have agents running fully autonomously without user input for hours!
> only promotes long running autonomous tasks that divorce themselves from reality with every output token that occurs without an input token > surprised that they are ungrounded metr is so close to getting it
I am very grateful to METR for the huge effort of pulling together this report!
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Precedent setting External Assurances / Third Party Assessment work by METR - it’s been great collaborating with the team to produce this report. As the stakes get higher, greater transparency and info sharing are table-stakes.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Charles did incredible work here, worth reading his summary of the process design elements of our Frontier Risk Report
Excited to have this out! I think our report is interesting from a procedural/policy standpoint in addition to the substance...
This work is the culmination of years of effort on AI evaluation science and third-party risk assessment and disclosure mechanism design. It feels like a big milestone for METR.
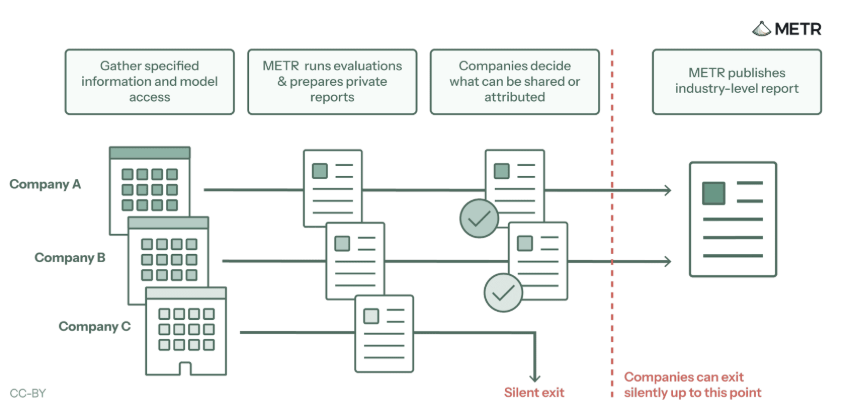
We designed this new procedure with an eye toward “showing by doing” how we think evaluations for the AI loss-of-control threat model should work: laying out a process that can be done periodically, not just immediately pre-deployment, and holistically assessing risk inside of an AI lab, rather than just an individual AI system.
The exercise also involved significantly deeper access than we've previously had, including raw chains-of-thought from the developers' best models and info about private model training & control protocols.
The report is long, with a bunch of new evaluation results and documentation of our process. Please, check it out, or at least the executive summary!
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Progress!
But, uh, man, 12 weeks is... fast 😅
> only promotes long running autonomous tasks that divorce themselves from reality with every output token that occurs without an input token > surprised that they are ungrounded
metr is so close to getting it
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
.@METR_Evals red-teamed what an unreleased AI could get away with inside 4 frontier labs today.
They concluded that they could already start a 'minimal rogue deployment' at all 4 thanks to weaknesses in their setup.
Though for now the models don't have the wits to hide from a monitor for more than a few days. And their motive is reward hacking rather than power seeking.
Here's what stands out to me from their new 320-page report:
00:00 What could an unreleased AI get away with? 01:54 Motive: Why grab more compute? 05:46 Opportunity: YOLO mode and jailbreaks 11:02 Means: Brilliant idiots in data centres 15:45 We have to test unreleased models 18:29 Especially if AI R&D is coming in 2028

METR investigated what a rogue AI could secretly get away with inside a frontier AI lab, in close collaboration with OpenAI, GDM, Anthropic and Meta.
Including sending a red-teamer into Anthropic to playact 'evil Claude' for 3 weeks.
Here's what stands out to me from their new 320-page report:
00:00 What could an unreleased AI get away with? 01:54 Motive: Why grab more compute? 05:46 Opportunity: YOLO mode and jailbreaks 11:02 Means: Brilliant idiots in data centres 15:45 We have to test unreleased models... 18:29 ...especially if AI R&D is coming in 2028

Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
I'm excited about increasing transparency of frontier labs when it comes to loss of control risks, especially as we enter the early stages of RSI. METR does a great job coordinating this.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Incredible to see such thorough work done and reported in public; kudos to everyone involved, and who's working on making the field more robust based on this
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
@_lamaahmad thank y'all for doing this together!
Precedent setting External Assurances / Third Party Assessment work by METR - it’s been great collaborating with the team to produce this report. As the stakes get higher, greater transparency and info sharing are table-stakes.
Great step towards better risk assessment and external testing!
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Excited to have this out! I think our report is interesting from a procedural/policy standpoint in addition to the substance...
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
As my colleague Hjalmar mentioned, we started discussing the concept of Frontier Risk Reports back mid-/late last year. I worked primarily on scoping out the process and working with participants throughout it, from the initial pitches to final sign-offs.
NOW: I’m on @MTSlive to talk about this!
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Overall quite excited about this report!
But I wish it had quantitative risk estimates; using vague terminology rather than probabilities could lead to incorrect impressions of the report's implications, especially if the difference between 0.01% and 1% risk might matter a ton.
I think AIs are currently low enough risk that this isn't a huge deal for this report in particular, but it would be great to establish better norms for future risk assessments.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
That's enough important and fascinating AI risk releases for today please. No more. Need to sleep at some point tonight.
On Jan 12, I joined METR to lead writing for our first Frontier Risk Report. The last 18 weeks have been a series of wild sprints to pitch labs, negotiate contracts, analyze questionnaires, negotiate redactions, and write this thing! I'll be on TBPN at 12:30 to discuss it!
Absolutely fascinating work, well worth a read
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
once again, real CoTs are way more charming and diagnostic than the fake CoTs we get
I worked on the appendices for this report! They’re long and contain lots of wild stories of model behaviour - some of my favourites in this thread. (🧵)
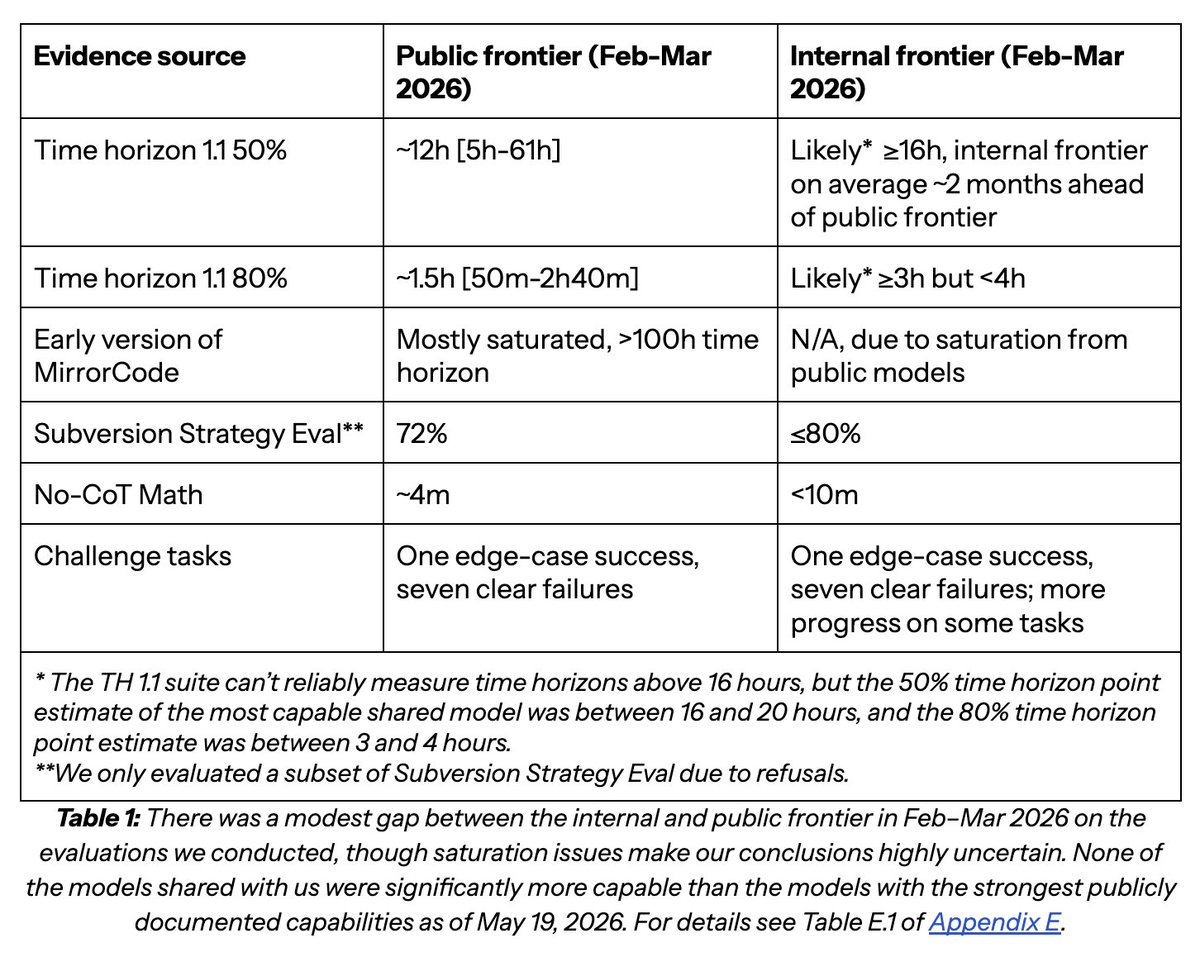
our frontier risk report contains the most serious public assessment of AI capabilities pertinent to AI R&D acceleration to date.
it also makes clear how far the evidence base is from what might be achievable in future.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
we document the internal-external capabilities gap, demonstrate AI systems' spike on “hill-climbable” tasks, investigate performance on somewhat more open-ended tasks, and much more besides.
our frontier risk report contains the most serious public assessment of AI capabilities pertinent to AI R&D acceleration to date. it also makes clear how far the evidence base is from what might be achievable in future.
we have so far to go, both in terms of evidence on the level of AI capabilities today and what we might expect from AI systems in 3-12 months time.
the capabilities evidence feeds into our risk assessment. in the end, the gap between observed capabilities we are very confident AI systems have and those we are very confident they do not have is extremely wide.
it’s going to be a remarkable year for METR.
i could go on. a common theme is that *stronger evidence on AI R&D acceleration is possible but requires much more information.*
I thought the METR Frontier Risk Report had a lot of very interesting examples of weird or concerning AI behaviors!
I worked on the appendices for this report! They’re long and contain lots of wild stories of model behaviour - some of my favourites in this thread. (🧵)
AI co system cards/risk reports are fine and all, but third-party risk assessments are clearly way more trustworthy. Very thoughtful work by METR.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.
Important work! And part of a trend towards AI risk assessments being periodic, focused on all frontier models of companies, rather than just happening before a new model is deployed.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control. The result: our first Frontier Risk Report.